คำถามนี้เกิดขึ้นจากความสับสนที่แท้จริงของฉันเกี่ยวกับวิธีการตัดสินใจว่าแบบจำลองโลจิสติกส์นั้นดีพอหรือไม่ ฉันมีรูปแบบที่ใช้สถานะของคู่แต่ละโครงการสองปีหลังจากที่พวกเขาจะกลายเป็นตัวแปรตาม ผลลัพธ์สำเร็จ (1) หรือไม่ (0) ฉันมีตัวแปรอิสระที่วัดได้ในเวลาที่ทำการก่อตัวของคู่ เป้าหมายของฉันคือการทดสอบว่าตัวแปรที่ฉันตั้งสมมติฐานจะมีอิทธิพลต่อความสำเร็จของคู่นั้นมีผลต่อความสำเร็จนั้นหรือไม่ควบคุมอิทธิพลที่อาจเกิดขึ้นอื่น ๆ ในโมเดลตัวแปรที่น่าสนใจมีความสำคัญ
รุ่นได้ประมาณโดยใช้ฟังก์ชั่นในglm() Rเพื่อประเมินคุณภาพของรูปแบบที่ฉันได้ทำสิ่งที่ไม่กี่: glm()ช่วยให้คุณresidual devianceที่AICและBICตามค่าเริ่มต้น นอกจากนี้ฉันได้คำนวณอัตราความผิดพลาดของแบบจำลองและพล็อตสิ่งที่เหลือค้างแล้ว
- แบบจำลองที่สมบูรณ์มีความเบี่ยงเบนที่เหลืออยู่น้อยกว่า AIC และ BIC กว่าแบบจำลองอื่น ๆ ที่ฉันได้ประเมินไว้ (และซ้อนอยู่ในแบบจำลองที่สมบูรณ์) ซึ่งทำให้ฉันคิดว่าแบบจำลองนี้ "ดีกว่า" กว่าคนอื่น ๆ
- อัตราความผิดพลาดของโมเดลค่อนข้างต่ำ IMHO (เช่นเดียวกับGelman and Hill, 2007, pp.99 ):
error.rate <- mean((predicted>0.5 & y==0) | (predicted<0.5 & y==1)ที่ประมาณ 20%
จนถึงตอนนี้ดีมาก แต่เมื่อฉันพล็อตสิ่งที่เหลือค้าง (อีกครั้งตามคำแนะนำของ Gelman และ Hill) ส่วนใหญ่ของถังขยะจะตกนอก 95% CI:
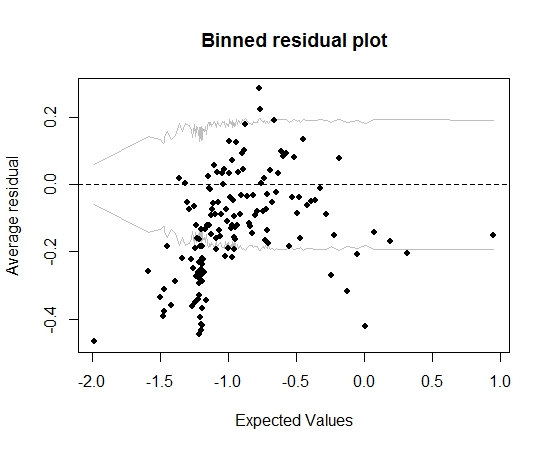
เนื้อเรื่องนั้นทำให้ฉันคิดว่ามีบางอย่างผิดปกติเกี่ยวกับตัวแบบ นั่นควรทำให้ฉันต้องโยนโมเดลออกไปหรือไม่? ฉันควรรับทราบหรือไม่ว่าโมเดลนั้นมีข้อบกพร่อง แต่เก็บไว้และตีความผลของตัวแปรที่น่าสนใจ ฉันเล่นรอบ ๆ โดยไม่รวมตัวแปรในทางกลับกันและการเปลี่ยนแปลงบางอย่าง
แก้ไข:
- ในขณะนี้แบบจำลองมีตัวทำนายโหลและเอฟเฟกต์การโต้ตอบ 5 รายการ
- คู่เป็น "ค่อนข้าง" เป็นอิสระจากกันในแง่ที่ว่าพวกเขาจะเกิดขึ้นในช่วงเวลาสั้น ๆ (แต่ไม่พูดอย่างเคร่งครัดพร้อมกันทั้งหมด) และมีโครงการจำนวนมาก (13k) และบุคคลจำนวนมาก (19k ) ดังนั้นสัดส่วนที่ยุติธรรมของโครงการจะเข้าร่วมโดยบุคคลเดียวเท่านั้น (มีประมาณ 20,000 คู่)