ในโรงเรียนทั่วโลกเด็ก ๆ พิมพ์ตัวเลขลงในเครื่องคิดเลข LCD พลิกคว่ำและปะทุเป็นเสียงหัวเราะหลังจากสร้างคำว่า 'เต้า' แน่นอนว่านี่เป็นคำที่นิยมมากที่สุด แต่ก็มีอีกหลายคำที่สามารถสร้างได้
อย่างไรก็ตามคำทั้งหมดต้องมีความยาวน้อยกว่า 10 ตัวอักษร (พจนานุกรมมีคำที่ยาวกว่านี้อย่างไรก็ตามคุณต้องดำเนินการตัวกรองในโปรแกรมของคุณ) ในพจนานุกรมนี้มีคำที่เป็นตัวพิมพ์ใหญ่บางคำดังนั้นแปลงทุกคำเป็นตัวพิมพ์เล็ก
ใช้พจนานุกรมภาษาอังกฤษสร้างรายการตัวเลขที่สามารถพิมพ์ลงในเครื่องคิดเลข LCD และสร้างคำได้ เช่นเดียวกับคำถามทั้งหมดเกี่ยวกับกอล์ฟโปรแกรมที่สั้นที่สุดที่จะทำให้งานนี้สำเร็จลุล่วง
สำหรับการทดสอบของฉันฉันใช้รายการคำ UNIX ที่รวบรวมโดยการพิมพ์:
ln -s /usr/dict/words w.txt
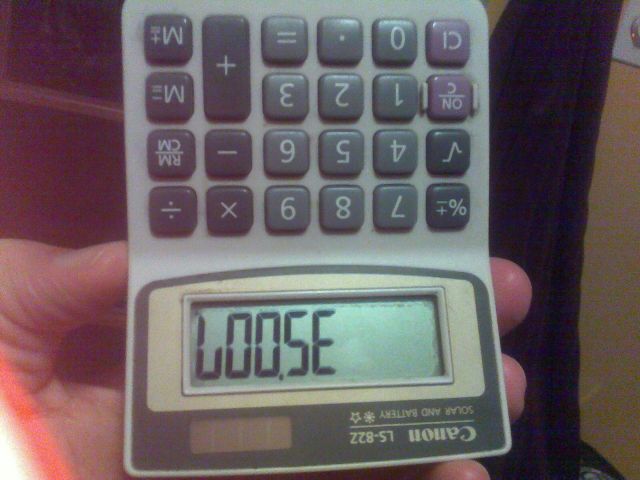
ตัวอย่างเช่นภาพด้านบนถูกสร้างขึ้นโดยการพิมพ์หมายเลข35007ลงในเครื่องคิดเลขและพลิกกลับด้าน
ตัวอักษรและตัวเลขที่เกี่ยวข้อง:
- ข :
8 - g :
6 - l :
7 - ฉัน :
1 - o :
0 - s :
5 - z :
2 - ชม. :
4 - e :
3
โปรดทราบว่าหากตัวเลขเริ่มต้นด้วยศูนย์จำเป็นต้องมีจุดทศนิยมหลังจากศูนย์นั้น จำนวนต้องไม่เริ่มต้นด้วยจุดทศนิยม
ฉันคิดว่านี่เป็นรหัสของMartinBüttnerแค่อยากให้เครดิตคุณ :)
/* Configuration */
var QUESTION_ID = 51871; // Obtain this from the url
// It will be like http://XYZ.stackexchange.com/questions/QUESTION_ID/... on any question page
var ANSWER_FILTER = "!t)IWYnsLAZle2tQ3KqrVveCRJfxcRLe";
/* App */
var answers = [], page = 1;
function answersUrl(index) {
return "http://api.stackexchange.com/2.2/questions/" + QUESTION_ID + "/answers?page=" + index + "&pagesize=100&order=desc&sort=creation&site=codegolf&filter=" + ANSWER_FILTER;
}
function getAnswers() {
jQuery.ajax({
url: answersUrl(page++),
method: "get",
dataType: "jsonp",
crossDomain: true,
success: function (data) {
answers.push.apply(answers, data.items);
if (data.has_more) getAnswers();
else process();
}
});
}
getAnswers();
var SIZE_REG = /\d+(?=[^\d&]*(?:<(?:s>[^&]*<\/s>|[^&]+>)[^\d&]*)*$)/;
var NUMBER_REG = /\d+/;
var LANGUAGE_REG = /^#*\s*([^,]+)/;
function shouldHaveHeading(a) {
var pass = false;
var lines = a.body_markdown.split("\n");
try {
pass |= /^#/.test(a.body_markdown);
pass |= ["-", "="]
.indexOf(lines[1][0]) > -1;
pass &= LANGUAGE_REG.test(a.body_markdown);
} catch (ex) {}
return pass;
}
function shouldHaveScore(a) {
var pass = false;
try {
pass |= SIZE_REG.test(a.body_markdown.split("\n")[0]);
} catch (ex) {}
return pass;
}
function getAuthorName(a) {
return a.owner.display_name;
}
function process() {
answers = answers.filter(shouldHaveScore)
.filter(shouldHaveHeading);
answers.sort(function (a, b) {
var aB = +(a.body_markdown.split("\n")[0].match(SIZE_REG) || [Infinity])[0],
bB = +(b.body_markdown.split("\n")[0].match(SIZE_REG) || [Infinity])[0];
return aB - bB
});
var languages = {};
var place = 1;
var lastSize = null;
var lastPlace = 1;
answers.forEach(function (a) {
var headline = a.body_markdown.split("\n")[0];
//console.log(a);
var answer = jQuery("#answer-template").html();
var num = headline.match(NUMBER_REG)[0];
var size = (headline.match(SIZE_REG)||[0])[0];
var language = headline.match(LANGUAGE_REG)[1];
var user = getAuthorName(a);
if (size != lastSize)
lastPlace = place;
lastSize = size;
++place;
answer = answer.replace("{{PLACE}}", lastPlace + ".")
.replace("{{NAME}}", user)
.replace("{{LANGUAGE}}", language)
.replace("{{SIZE}}", size)
.replace("{{LINK}}", a.share_link);
answer = jQuery(answer)
jQuery("#answers").append(answer);
languages[language] = languages[language] || {lang: language, user: user, size: size, link: a.share_link};
});
var langs = [];
for (var lang in languages)
if (languages.hasOwnProperty(lang))
langs.push(languages[lang]);
langs.sort(function (a, b) {
if (a.lang > b.lang) return 1;
if (a.lang < b.lang) return -1;
return 0;
});
for (var i = 0; i < langs.length; ++i)
{
var language = jQuery("#language-template").html();
var lang = langs[i];
language = language.replace("{{LANGUAGE}}", lang.lang)
.replace("{{NAME}}", lang.user)
.replace("{{SIZE}}", lang.size)
.replace("{{LINK}}", lang.link);
language = jQuery(language);
jQuery("#languages").append(language);
}
}body { text-align: left !important}
#answer-list {
padding: 10px;
width: 50%;
float: left;
}
#language-list {
padding: 10px;
width: 50%px;
float: left;
}
table thead {
font-weight: bold;
}
table td {
padding: 5px;
}<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<link rel="stylesheet" type="text/css" href="//cdn.sstatic.net/codegolf/all.css?v=83c949450c8b">
<div id="answer-list">
<h2>Leaderboard</h2>
<table class="answer-list">
<thead>
<tr><td></td><td>Author</td><td>Language</td><td>Size</td></tr>
</thead>
<tbody id="answers">
</tbody>
</table>
</div>
<div id="language-list">
<h2>Winners by Language</h2>
<table class="language-list">
<thead>
<tr><td>Language</td><td>User</td><td>Score</td></tr>
</thead>
<tbody id="languages">
</tbody>
</table>
</div>
<table style="display: none">
<tbody id="answer-template">
<tr><td>{{PLACE}}</td><td>{{NAME}}</td><td>{{LANGUAGE}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr>
</tbody>
</table>
<table style="display: none">
<tbody id="language-template">
<tr><td>{{LANGUAGE}}</td><td>{{NAME}}</td><td>{{SIZE}}</td><td><a href="{{LINK}}">Link</a></td></tr>
</tbody>
</table>0.7734ว่าhelloหรือจะ.7734ยอมรับได้ไหม?
0.7734ต้องการ
oligoต้องการศูนย์ต่อท้ายหลังจุดทศนิยม:0.6170