ฉันต้องการตรวจสอบชื่อโดเมน:
google.com
stackoverflow.com
ดังนั้นโดเมนในรูปแบบที่ดิบที่สุดไม่ใช่แม้แต่โดเมนย่อยเช่น www
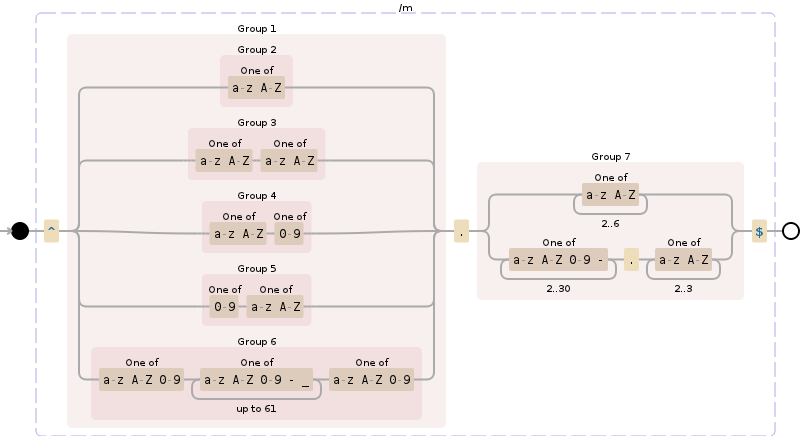
- อักขระควรเป็นaz | AZ | 0-9และระยะเวลา (.) และขีด (-)
- ส่วนของชื่อโดเมนไม่ควรขึ้นต้นหรือลงท้ายด้วยเครื่องหมายขีด (-) (เช่น -google-.com)
- ส่วนของชื่อโดเมนควรมีความยาวระหว่าง 1 ถึง 63 อักขระ
ส่วนขยาย (TLD) อาจเป็นอะไรก็ได้ภายใต้กฎ # 1 ในตอนนี้ฉันสามารถตรวจสอบความถูกต้องกับรายการในภายหลังได้ แต่ควรมี 1 อักขระขึ้นไป
แก้ไข: TLD เห็นได้ชัดว่าเป็น 2-6 ตัวอักษรตามที่ระบุ
ไม่ แก้ไข 4 ครั้ง: TLD ควรมีป้ายกำกับว่า "โดเมนย่อย" ตามที่ควรมีเช่น. co.uk - ฉันคิดว่าการตรวจสอบความถูกต้องเดียวที่เป็นไปได้ (นอกเหนือจากการตรวจสอบกับรายการ) จะเป็น "หลังจากจุดแรกควรมีอย่างใดอย่างหนึ่งหรือ อักขระเพิ่มเติมภายใต้กฎ # 1
ขอบคุณมากเชื่อฉันฉันได้ลอง!
1
อาจไม่เป็นประโยชน์เลย เมื่อพูดถึง google.co.uk และโดเมนภาษาญี่ปุ่นบางโดเมนฉันแน่ใจว่าคุณจะต้องคิดให้ดีก่อนที่จะใช้ regex ความคิดส่วนตัวของฉันคือ regex ไม่เพียงพอที่จะตรวจสอบโดเมนกับโดเมนในชีวิตจริง FYI นี่คือรายการโดเมนระดับที่สองของ tlds และรหัสประเทศเกือบทั้งหมด: static.ayesh.me/misc/SO/tlds.txt
—
Ayesh K
—
SAM
มักถูกลืม: สำหรับชื่อโดเมนแบบเต็มคุณควรจับคู่ช่วงเวลาหลัง tld
—
schmijos
เป็นเวลา 4 ปีแล้วตอนนี้นับได้ถึง 89,000
—
mydoglixu
คำตอบเหล่านี้บางคำค่อนข้างดี แต่ก็มีอีกคำตอบที่ดีสำหรับคำถามอื่น ๆที่น่าดู
—
craftworkgames