ฉันมีคำถามนี้มาหลายเดือนแล้ว ดูเหมือนว่าเราเพิ่งจะคาดเดา softmax เป็นฟังก์ชันเอาต์พุตอย่างชาญฉลาดแล้วตีความอินพุตให้ softmax เป็นความน่าจะเป็นบันทึก อย่างที่คุณพูดทำไมไม่เอามาตรฐานทั้งหมดออกมาโดยหารด้วยผลรวมของพวกมัน? ฉันพบคำตอบในหนังสือเรียนรู้ลึกโดย Goodfellow, Bengio และ Courville (2016) ในหัวข้อ 6.2.2
สมมติว่าเลเยอร์ที่ซ่อนสุดท้ายของเราทำให้เราเปิดใช้งานได้ จากนั้นกำหนด softmax เป็น

คำอธิบายสั้นมาก
exp ในฟังก์ชั่น softmax จะตัดการบันทึกอย่างคร่าว ๆ ในการสูญเสียข้ามเอนโทรปีทำให้การสูญเสียจะเป็นเส้นตรงใน z_i สิ่งนี้นำไปสู่การไล่ระดับคงที่อย่างคร่าวๆเมื่อแบบจำลองผิดพลาดทำให้สามารถแก้ไขตัวมันเองได้อย่างรวดเร็ว ดังนั้น softmax อิ่มตัวที่ไม่ถูกต้องจะไม่ทำให้การไล่ระดับสีหายไป
คำอธิบายสั้น ๆ
วิธีที่นิยมที่สุดในการฝึกอบรมโครงข่ายประสาทเทียมคือการประมาณความน่าจะเป็นสูงสุด เราประเมินพารามิเตอร์ทีในวิธีที่เพิ่มความน่าจะเป็นของข้อมูลการฝึกอบรม (ขนาด m) เนื่องจากความน่าจะเป็นของชุดข้อมูลการฝึกอบรมทั้งหมดเป็นผลมาจากความน่าจะเป็นของตัวอย่างแต่ละชุดมันจะง่ายต่อการเพิ่มความน่าจะเป็นบันทึกของชุดข้อมูลและผลรวมของความน่าจะเป็นบันทึกของแต่ละตัวอย่างที่จัดทำดัชนีโดย k:
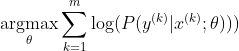
ตอนนี้เรามุ่งเน้นไปที่ softmax ที่นี่ด้วย z ที่ให้ไปแล้วเพื่อให้เราสามารถแทนที่
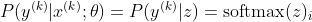
โดยที่ฉันเป็นคลาสที่ถูกต้องของตัวอย่าง kth ตอนนี้เราจะเห็นว่าเมื่อเราใช้ลอการิทึมของ softmax เพื่อคำนวณความน่าจะเป็นบันทึกของตัวอย่างเราจะได้รับ:
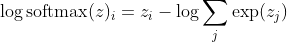
ซึ่งสำหรับความแตกต่างขนาดใหญ่ใน z ประมาณใกล้เคียงกับ
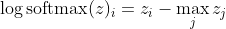
อันดับแรกเราจะเห็นองค์ประกอบเชิงเส้น z_i ที่นี่ ประการที่สองเราสามารถตรวจสอบพฤติกรรมของ max (z) สำหรับสองกรณี:
- หากโมเดลนั้นถูกต้องแล้ว max (z) จะเป็น z_i ดังนั้น log-likelihood asymptotes zero (เช่นความน่าจะเป็นที่ 1) ที่มีความแตกต่างเพิ่มขึ้นระหว่าง z_i และรายการอื่น ๆ ใน z
- หากโมเดลไม่ถูกต้องค่าสูงสุด (z) จะเป็น z_j> z_i อื่น ๆ ดังนั้นการเพิ่ม z_i ไม่ได้ยกเลิก -z_j อย่างสมบูรณ์และบันทึกความน่าจะเป็นคือประมาณ (z_i - z_j) สิ่งนี้บอกรูปแบบได้อย่างชัดเจนว่าควรทำอย่างไรเพื่อเพิ่มความน่าจะเป็นในการบันทึก: เพิ่ม z_i และลด z_j
เราจะเห็นว่าตัวอย่างความน่าจะเป็นจะถูกครอบงำโดยกลุ่มตัวอย่างซึ่งรูปแบบไม่ถูกต้อง นอกจากนี้แม้ว่ารูปแบบจะไม่ถูกต้องจริง ๆ ซึ่งนำไปสู่ softmax อิ่มตัวฟังก์ชั่นการสูญเสียไม่อิ่มตัว มันเป็นเส้นตรงใน z_j ซึ่งหมายความว่าเรามีการไล่ระดับสีอย่างคงที่ สิ่งนี้ทำให้โมเดลสามารถแก้ไขตัวเองได้อย่างรวดเร็ว โปรดทราบว่านี่ไม่ใช่กรณีของ Mean Squared Error เช่น
คำอธิบายยาว
หาก softmax ยังคงเป็นตัวเลือกตามอำเภอใจสำหรับคุณคุณสามารถดูเหตุผลในการใช้ sigmoid ในการถดถอยโลจิสติก:
ทำไม sigmoid จึงทำงานแทนอย่างอื่น?
softmax เป็นลักษณะทั่วไปของ sigmoid สำหรับปัญหาหลายชั้นที่ถูกต้องแบบอะนาล็อก



