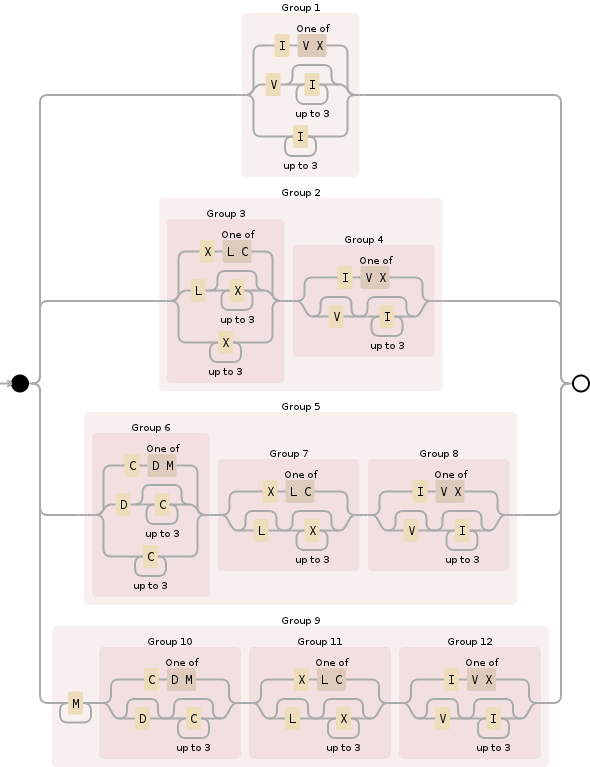
คุณสามารถใช้ regex ต่อไปนี้:
^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$
ทำลายมันลงM{0,4}ระบุส่วนพันและพื้นยับยั้งมันระหว่างและ0 4000มันค่อนข้างง่าย:
0: <empty> matched by M{0}
1000: M matched by M{1}
2000: MM matched by M{2}
3000: MMM matched by M{3}
4000: MMMM matched by M{4}
แน่นอนคุณสามารถใช้บางสิ่งบางอย่างเช่นM*อนุญาตให้มีตัวเลขใด ๆ (รวมถึงศูนย์) ของหลักพันหากคุณต้องการอนุญาตตัวเลขที่ใหญ่กว่า
ถัดไปคือ(CM|CD|D?C{0,3})ซับซ้อนกว่านี้เล็กน้อยสำหรับส่วนร้อยและครอบคลุมความเป็นไปได้ทั้งหมด:
0: <empty> matched by D?C{0} (with D not there)
100: C matched by D?C{1} (with D not there)
200: CC matched by D?C{2} (with D not there)
300: CCC matched by D?C{3} (with D not there)
400: CD matched by CD
500: D matched by D?C{0} (with D there)
600: DC matched by D?C{1} (with D there)
700: DCC matched by D?C{2} (with D there)
800: DCCC matched by D?C{3} (with D there)
900: CM matched by CM
ประการที่สาม(XC|XL|L?X{0,3})ปฏิบัติตามกฎเดียวกันกับส่วนก่อนหน้า แต่สำหรับหลักสิบ:
0: <empty> matched by L?X{0} (with L not there)
10: X matched by L?X{1} (with L not there)
20: XX matched by L?X{2} (with L not there)
30: XXX matched by L?X{3} (with L not there)
40: XL matched by XL
50: L matched by L?X{0} (with L there)
60: LX matched by L?X{1} (with L there)
70: LXX matched by L?X{2} (with L there)
80: LXXX matched by L?X{3} (with L there)
90: XC matched by XC
และสุดท้าย(IX|IV|V?I{0,3})เป็นส่วนที่หน่วยจัดการ0ผ่าน9และยังคล้ายกับก่อนหน้านี้สองส่วน (เลขโรมันแม้จะมีความแปลกประหลาดที่เห็นพวกเขาปฏิบัติตามกฎตรรกะบางอย่างเมื่อคุณคิดออกสิ่งที่พวกเขา):
0: <empty> matched by V?I{0} (with V not there)
1: I matched by V?I{1} (with V not there)
2: II matched by V?I{2} (with V not there)
3: III matched by V?I{3} (with V not there)
4: IV matched by IV
5: V matched by V?I{0} (with V there)
6: VI matched by V?I{1} (with V there)
7: VII matched by V?I{2} (with V there)
8: VIII matched by V?I{3} (with V there)
9: IX matched by IX
เพียงจำไว้ว่า regex นั้นจะจับคู่สตริงว่าง หากคุณไม่ต้องการสิ่งนี้ (และเอ็นจิ้น regex ของคุณทันสมัยพอ) คุณสามารถใช้การมองย้อนกลับและมองไปข้างหน้าในเชิงบวก:
(?<=^)M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})(?=$)
(อีกทางเลือกหนึ่งคือเพียงแค่ตรวจสอบว่าความยาวไม่ได้เป็นศูนย์ล่วงหน้า)