พวกเขาเป็นสองตัวชี้วัดที่แตกต่างกันในการประเมินประสิทธิภาพของแบบจำลองของคุณมักจะใช้ในขั้นตอนที่แตกต่างกัน
การสูญเสียมักใช้ในกระบวนการฝึกอบรมเพื่อค้นหาค่าพารามิเตอร์ "ดีที่สุด" สำหรับแบบจำลองของคุณ (เช่นน้ำหนักในเครือข่ายประสาทเทียม) มันเป็นสิ่งที่คุณพยายามเพิ่มประสิทธิภาพในการฝึกอบรมโดยการปรับปรุงน้ำหนัก
ความแม่นยำเป็นมากกว่ามุมมองที่ใช้ เมื่อคุณพบพารามิเตอร์ที่ปรับให้เหมาะสมด้านบนแล้วคุณจะใช้เมตริกนี้เพื่อประเมินความแม่นยำของการทำนายแบบจำลองของคุณกับข้อมูลจริง
ให้เราใช้ตัวอย่างการจำแนกของเล่น คุณต้องการทำนายเพศจากน้ำหนักและส่วนสูง คุณมี 3 ข้อมูลพวกเขามีดังนี้: (0 หมายถึงชาย, 1 หมายถึงหญิง)
y1 = 0, x1_w = 50kg, x2_h = 160cm;
y2 = 0, x2_w = 60kg, x2_h = 170cm;
y3 = 1, x3_w = 55kg, x3_h = 175cm;
คุณใช้โมเดลการถดถอยแบบโลจิสติกส์แบบง่ายนั่นคือ y = 1 / (1 + exp- (b1 * x_w + b2 * x_h))
คุณหา b1 และ b2 ได้อย่างไร คุณกำหนดความสูญเสียก่อนและใช้วิธีการปรับให้เหมาะสมเพื่อลดการสูญเสียในแบบวนซ้ำโดยการอัพเดต b1 และ b2
ในตัวอย่างของเราการสูญเสียโดยทั่วไปสำหรับปัญหาการจำแนกเลขฐานสองนี้อาจเป็น: (ควรลบเครื่องหมายลบหน้าเครื่องหมายสรุป)

เราไม่รู้ว่า b1 และ b2 ควรเป็นอย่างไร ให้เราทำการสุ่มเลือกว่า b1 = 0.1 และ b2 = -0.03 ถ้าอย่างนั้นการสูญเสียของเราคืออะไร?
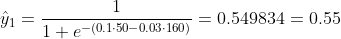
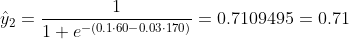
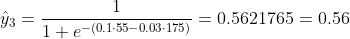
ดังนั้นการสูญเสียคือ
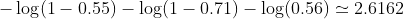
จากนั้นคุณเรียนรู้อัลกอริทึม (เช่นการไล่ระดับสี) จะค้นหาวิธีในการอัปเดต b1 และ b2 เพื่อลดการสูญเสีย
จะเกิดอะไรขึ้นถ้า b1 = 0.1 และ b2 = -0.03 คือ b1 และ b2 สุดท้าย (ผลลัพธ์จากการไล่ระดับสี) ความแม่นยำตอนนี้คืออะไร?
สมมุติว่า y_hat> = 0.5 เราจะตัดสินว่าคำทำนายของเราคือเพศหญิง (1) มิฉะนั้นจะเป็น 0 ดังนั้นอัลกอริทึมของเราทำนาย y1 = 1, y2 = 1 และ y3 = 1. ความแม่นยำของเราคืออะไร? เราทำการทำนายผิดบน y1 และ y2 และทำการแก้ไขให้ถูกต้องใน y3 ดังนั้นตอนนี้ความแม่นยำของเราคือ 1/3 = 33.33%
ป.ล. : ในคำตอบของอาเมียร์การกล่าวถึงการขยายพันธุ์กลับเป็นวิธีการหาค่าเหมาะที่สุดใน NN ฉันคิดว่ามันจะถูกมองว่าเป็นวิธีการไล่ระดับสีสำหรับตุ้มน้ำหนักใน NN วิธีการปรับให้เหมาะสมทั่วไปใน NN คือ GradientDescent และ Adam
